
За фасадом искусственного «интеллекта»

Сама по себе настоящая статья на актуальную тему несколько выбивается из ряда обычных наших публикаций своим размером и своей профессиональной точностью в описании деталей. Хотя для людей, имеющих общее математическое образование, ничего сложного в ней нет. Она требует лишь внимания, терпения и привычки к умственной работе. Но важность освещаемой темы для современников убеждает нас в том, что многие готовы будут прочитать статью, чтобы понять, что же такое этот ИИ, о котором так много говорят в последнее время, возлагая на не него нередко непомерные надежды. При этом в своём повествовании автор идёт последовательно, показывая этапы его происхождения, делая очевидными выводы, и приводя читателя к знанию предмета, в чем может быть польза и опасность этого инструмента и каковы ограничения на его применение.
Конечно, ИИ – это не интеллект вовсе, его нельзя сравнивать с человеческим природным. И главное, если кто-то бездумно доверится ему, то постепенно потеряет связь с реальностью и, что важно, оглупит себя. снизив свои природные способности к познанию и пониманию мира. Обо всем этом, а также о духовных последствиях модного увлечения читайте в публикуемой нами статье. – Редакция СР.
10 февраля 2026 года в канадском городке Тамблер-Ридж некий 18-летний Джесси Ван Рутселаар убил свою мать и 11-летнего сводного брата. Не остановившись на достигнутом, убийца отправился в рядом находящуюся школу и открыл прицельный огонь, убив пятерых детей и учителя, и ранив еще более двух десятков детей. Затем стрелок самоликвидировался выстрелом в голову. В сообщениях англоязычных СМИ стрелок описывался, как женщина, т.е. это был трансгендер, а попросту – психически больной молодой человек, который начал «трансгендерный переход» в 12-летнем возрасте.
Интерес этот ужасный случай представляет не только фактом массового убийства, но и неожиданными извинениями главы компании OpenAI Сэма Альтмана. 24 апреля (спустя два с половиной месяца после стрельбы) Альтман выразил соболезнования жителям городка. «Я глубоко сожалею, что мы не уведомили правоохранительные органы об учетной записи, заблокированной в июне», – сказал Альтман. Как выяснилось, Ван Рутселаар имел аккаунт (учетную запись) на сайте OpenAI, чтобы общаться с чат-ботом ИИ. Еще в июне 2025 года OpenAI идентифицировала учетную запись Ван Рутселаара с помощью средств обнаружения нарушений, связанных с «дальнейшим применением насилия». Однако эти данные не были переданы Канадской королевской полиции. За что Сэм Альтман и принес свои извинения, которые, откровенно говоря, теперь нужны как мертвому припарки.
Дадим небольшие объяснения, чтобы была понятнее суть происшествия. Американская компания OpenAI – один из флагманов индустрии «искусственного интеллекта». Главный ее продукт – чат-бот ChatGPT. Это т.н. генеративная модель, основанная на нейронной сети глубокого обучения. Компания была основана в 2015 году Илоном Маском и Сэмом Альтманом, как некоммерческое исследовательское партнерство. Взрыв интереса к компании произошел осенью 2020 года, после появления модели ChatGPT-3, которую многие студенты стали использовать для генерации рефератов и дипломным проектов.
На сегодня OpenAI является не единственной компанией, создающей продукты в сфере т.н. «генеративного искусственного интеллекта» (Generative artificial intelligence – Generative AI – GAI). Недавно американская компания Anthropic (тесно связанная с Пентагоном и ЦРУ), создающая свои AI-продукты, достигла капитализации в 1 триллион долларов, отодвинув OpenAI на второе место. Имеются мощные модели генеративного ИИ в Китае, например модель DeepSeek, которая постоянно «дышит в спину» ChatGPT.
За последние несколько лет в новостных лентах периодически появлялись сообщения о случаях убийств или самоубийств, которые совершали молодые люди, спланировавшие свои действия после длительного общения с теми или другими GAI-ботами, прежде всего, с ChatGPT. Каждый такой случай вызывает справедливую тревогу общественности и обещания руководителей компаний, занятых «искусственным интеллектом» (ИИ), внести коррективы в свои модели, чтобы не допустить подобных инцидентов в будущем. Но воз, как говорится, и ныне там. Чему свидетельство – массовый расстрел в Тамблер-Ридж.

Впрочем, большинство людей стараются не замечать этих «побочных эффектов» GAI. Миллионы людей по всему миру активно используют модели GAI для работы и развлечений. Кто-то при помощи тех или иных моделей оптимизирует свои бизнес-процессы. А еще большее число людей генерируют («генерят», как выражаются пользователи) забавные картинки и видео, например, при помощи модели Nano Banana компании Google (официально последняя модель называется Gemini). По последним отчетам, более половины всех видео на таких площадках, как YouTube и TikToke – это ролики, сгенерированные при помощи тех или иных GAI-моделей. «Искусственный интеллект» (во всех его ипостасях) сейчас захватывает все больше и больше сегментов мировой экономики и общественной жизни. Звучат отдельные голоса об опасности этой технологии для человечества. В ответ дружный хор любителей смешных роликов с TikTok обвиняют таких людей в консервативности мышления, конспирологии и умственных отклонениях. В самом деле, люди веселятся, делают смешные видеоролики и забавные картинки, а кто-то пытается в эту огромную бочку мёда подмешать свою ложку дегтя.
Так что же такое – «искусственный интеллект»? Как он устроен и что можно от него ожидать в ближайшем будущем? Давайте попробуем разобраться.
Истоки
Можно ли создать копию человеческого мозга, то есть воспроизвести интеллект, разум человека? Для верующего человека ответ однозначен – нет. Только Господь наделяет живое существо душой и разумом. Попытка уподобиться Творцу – греховна в своей сути. Это равносильно попыткам древних алхимиков создать гомункула. Глиняный голем, якобы созданный в средневековой Праге раввином Лёвом – из той же серии. Сегодня, кажется, эти истории не воспринимаются иначе как сказки. Однако если нельзя искусственно создать интеллект, то, быть может, получится искусственно воссоздать какие-то его отдельные элементы? Ведь уже десятилетиями никого не удивляют целые роботизированные заводы, на которых почти нет людей, вся работа которых переложена на роботов – искусственные программируемые автоматы. Никого давно не удивляют компьютеры, которые быстро решают математические задачи, на выполнение которых людям прошлых веков потребовались бы годы. Эти электронные устройства работают на основе двоичной логики.
Первый автоматический двоичный аппарат предание связывает с папой Римским Сильвестром II, правившим с 999 по 1003 год. Сильвестр II интересовался науками и технологиями того времени и, как говорят, имел двоичный аппарат в виде бронзовой головы, которая могла отвечать на вопросы Да-Нет. Этого Папу подозревали в колдовстве, чернокнижии и чуть ли не общении с Сатаной. Сегодня проверить эти утверждения не представляется возможным.
Следующий шаг в развитии вычислительной техники, как считается, сделал Блез Паскаль. В 1642 году, решив помочь своему отцу, сборщику налогов, он сконструировал механическую суммирующую машину. В период до начала XX века появилось еще несколько изобретений, имевших цель облегчить умственную деятельность человека.
Не будем рассматривать все шаги, которые прошёл разум, прежде чем появились первые электронные вычислительные машины – ЭВМ, или, на английский манер – компьютеры (вычислители). К концу 1940-х годов все развитые страны уже имели собственные вычислительные машины (была такая машина и в СССР, МЭСМ – малая ЭВМ, которую начали создавать в 1949 году). Примерно в то же время среди ученых зарождающейся науки – информатики – возник отвлеченный вопрос: можно ли заставить компьютер «думать»? Вопрос этот, чисто теоретический, породил множество спекуляций и дал целое направление в научной фантастике. Однако практического решения не было. Слишком несовершенными были машины того периода.

В 1950 году британский математик Алан Тьюринг написал статью «Вычислительные машины и разум». В этой статье ученый сделал утверждение, что поскольку нельзя точно и однозначно определить, что такое «мышление», то от вопроса «может ли машина думать» надо перейти к другому – возможно ли создать такую систему, которая будет вести себя так, что сторонний наблюдатель, человек, не сможет отличить ее деятельность от обдуманной деятельности человека. Тьюринг предложил игру-имитацию. В игре три участника: два человека и ЭВМ. Они изолированы друг от друга. Испытатель посредством телетайпа попеременно задаёт вопросы другому человеку и машине, не зная точно, кого в данный момент опрашивает. Получая ответы – и от человека, и от машины – испытатель должен точно установить, какие ответы дала машина. Если он этого сделать не может – машина выиграла, то есть «одурачила» человека. Эта имитация вошла в историю под названием Теста Тьюринга. Тест Тьюринга стал интеллектуальным вызовом для ряда исследователей.
Не следует думать, однако, что развитие вычислительной техники было напрямую связано с идеей «думающей машины». История развития компьютеров шла по двум направлениям: создание все более совершенного аппаратного обеспечения («железо», hard) и программного обеспечения («софт»). За прошедшие десятилетия появилось большое количество языков программирования и операционных систем. Что касается аппаратного обеспечения, то довольно быстро компьютерное сообщество приняло т.н. архитектуру Фон Неймана. Джон фон Нейман – американский математик венгерско-еврейского происхождения, с 1943 года работал в составе группы Манхэттенского проекта (создание атомной бомбы в США). Для расчетов по этому проекту в 1945 году были созданы ЭВМ ENIAC и EDVAC. Основные принципы архитектуры этих машин фон Нейман, участвовавший в их создании, обобщил и предложил в качестве основы для любого универсального компьютера будущего. Как ни странно, эта архитектура (конечно, более усложненная) является основной любого современного компьютера и в наши дни, даже смартфона, который лежит в кармане, наверное, у каждого человека.
От года к году, от десятилетия к десятилетию ЭВМ уменьшались в размерах и становились все более быстрыми. Ламповые ЭВМ, которые занимали целые этажи зданий, сменились более компактными машинами на транзисторах. В ноябре 1971 года американская компания Intel выпустила первый в мире микропроцессор (он получил название Intel 4004). С этого момента началась эпоха микрокомпьютеров, то есть машин на базе микропроцессоров. Разумеется, такие компьютеры также становились все меньше, а скорость их работы все выше.
Ну а что же пресловутый «искусственный интеллект»? До поры работы в этом направлении носили отвлеченно-теоретический характер. Дело в том, что ни аппаратное обеспечение, когда-то крайне медленное и неуклюжее, ни базовые программные алгоритмы, не позволяли достаточно заметно продвинуться в сфере создания «думающей машины». Однако же компьютеры работали так, словно они «думали», появлялись даже компьютеры, которые могли обыграть в шахматы гроссмейстеров. Как же так? Этот момент требует отдельного объяснения.
Если – Иначе
Любая компьютерная программа, созданная в классической парадигме программирования, всегда работает по одной и той же схеме: она получает некоторые входные данные, затем обрабатывает их каким-то образом, после чего выдает выходные данные. Входные и выходные данные могут быть самыми произвольными: числа, наборы текстовых строк, фотографии, видео, звук.
Алгоритмы – это специальным образом описанные наборы команд для выполнения на компьютере. Алгоритмы могут быть очень сложными, состоять из тысяч и даже миллионов строк кода. При этом любая программа использует так называемые управляющие инструкции. Эти инструкции в целом сводятся к английской фразе IF – ELSE. Что означает: Если – иначе.
Например, программа в процессе каких-то математических расчетов получила некий результат, допустим, число. Далее программа в зависимости от того, положительное это число или отрицательное, должна сделать выбор, продолжить ли расчеты или завершить работу. Это может быть описано следующим образом:
Если число больше нуля – продолжить расчеты, иначе (т.е. оно равно нулю или отрицательное), завершить работу. Или, в более похожем на язык программирования виде: IF NUM > 0 ACT1 ELSE STOP.
Конкретные синтаксис зависел бы от того языка программирования, на котором написана программа. Но общее оставалось неизменным – программа постоянно проверяет какие-то условия при помощи IF – ELSE и принимает решение о дальнейших действиях.
Можно, например, запрограммировать игру «Крестики-нолики». В этой игре программа, прежде чем выбрать, в какой клетке поставить крестик (или нолик), при помощи множества конструкций IF – ELSE проверяет последствия такого хода. Например: «если эта клетка пустая и рядом стоит еще две пустые клетки, то поставить крестик, иначе – искать другую клетку». Когда человек будет играть с такой программой, он в самом деле будет ощущать, что компьютер «думает». Но на самом деле думает не компьютер, а программист, который ранее составил такую программу и учел (при помощи IF – ELSE) все возможные ситуации.
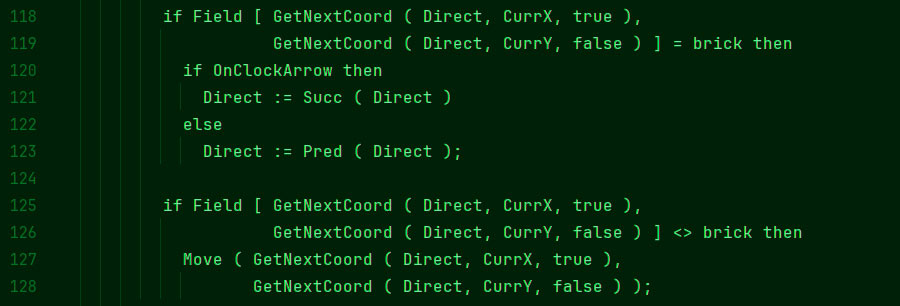
Разумеется, очень часто наша мыслительная деятельность может быть сведена к набору инструкций IF – ELSE. Например, в магазине мы ищем какой-то продукт из множества вариантов на полке, скажем, нам нужна сметана 15%. Мы просматриваем все варианты и подсознательно в мозгу работает нечто вроде: «Если на банке написано 15%, надо рассмотреть ее более подробно, иначе – искать дальше». Но вот банка сметаны 15% найдена. Да таких банок даже несколько под разными названиями. Дальше в мозгу может начаться что-то вроде: «Если цена ниже, чем у остальных, взять эту банку, иначе – смотреть цену следующей банки». Условие может быть усложнено, мозг может искать не только сметану с самой низкой ценой, но и самую свежую (что определяется по дате производства и сроку годности, то есть снова по числам). Конечно, средний покупатель не прокручивает в голове бесконечные «если – иначе», а делает свой выбор почти автоматически, на основе опыта. Однако компьютерную программу для покупки сметаны можно написать именно таким образом – на основе многочисленных инструкций IF – ELSE. Но будет ли это тем, что можно назвать «думающим компьютером»?
Ответ очевиден – нет. Потому что все эти многочисленные IF – ELSE не появляются в памяти компьютера в момент выполнения программы, а были запрограммированы человеком – программистом, который мысленно представлял себе весь ход покупки сметаны (или даже игры в шахматы), и скрупулезно описывал все возможные варианты при помощи управляющих инструкций. А эффект «думающего компьютера» возникал лишь благодаря высочайшей скорости работы процессора.
Высшей формой «искусственного интеллекта» на базе классического программирования (входные данные – алгоритмическая обработка – выходные данные) стали т.н. экспертные системы, ставшие очень популярными в конце 80-х годов XX века.
Представим себе врача, который пытается поставить точный диагноз пациенту с не очень понятной болезнью. Такой врач может опрашивать пациента на наличие тех или иных симптомов. Он может и сам получать дополнительную информацию – цвет белков глаз, состояние кожи, температуры и т.д. Собранные данные можно свести в большую таблицу симптомов, каждый из которых будет иметь метку ДА или НЕТ, то есть присутствует он у пациента или отсутствует. На основе всех симптомов врач поставит верный диагноз (если, конечно, имеет достаточную квалификацию). Сама собой напрашивается идея заменить врача компьютером, который будет опрашивать пациента, а затем на основе многочисленных IF – ELSE из своей базы знаний получит диагноз. Идея вполне рабочая. Есть только одно узкое место – программист ранее должен очень точно составить программу, чтобы она учитывала все возможные варианты симптомов. Если же у конкретного пациента присутствует симптом, который ранее не был учтен разработчиком такой программы – экспертной системы – то правильный диагноз не будет поставлен.
Мода на экспертные системы прошла довольно быстро. А вместе с ней и энтузиазм по поводу возможности создания «искусственного интеллекта».
Откуда же тогда появились современные модели «искусственного интеллекта», особенно генеративные модели? И вообще, что такое нейронные сети?
Идея персептрона
В 1940-х годах в США два американских нейробиолога Уоррен Маккалок и Уолтер Питтс проводили исследования с целью понять, как работает биологический мозг. Маккалок и Питтс не замахивались на то, чтобы объяснить процесс мышления. Их задача сводилась к чисто биологическим процессам распространения сигнала при помощи нейронов. Нейроны – это взаимосвязанные нервные клетки головного мозга, которые участвуют в обработке и передаче химических и электрических сигналов. В 1943 году исследователи опубликовали концепцию упрощенной клетки головного мозга, получившей название нейрона Маккалока-Питтса.
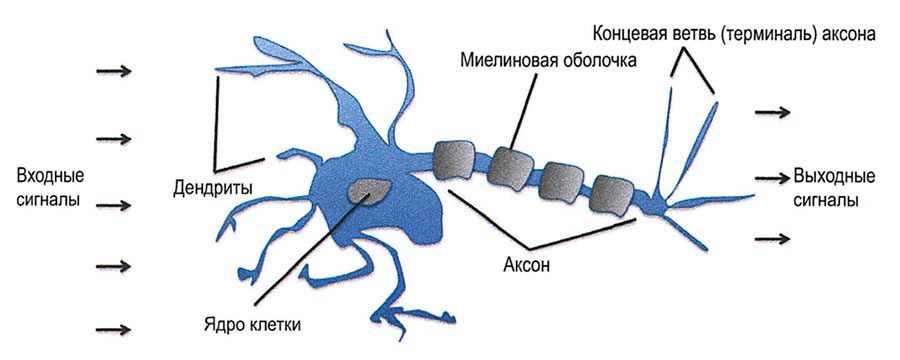
Упрощенная схема нейрона Маккалока-Питтса.
В их описании нейрон представляет из себя нечто вроде логического элемента (см.рис.). Сигналы поступают в дендриты (отростки нейрона) и переносятся в клеточное тело. Входной сигнал может накапливаться и преобразовывается в выходной сигнал при превышении некоторого порога. Далее он поступает в аксон (выходной отросток) для передачи дальше.
Исследования Маккалока и Питтса не были связаны с идеей «искусственного интеллекта», однако дали почву для размышлений тем, кого этот вопрос волновал. Таковым оказался молодой американский психолог Фрэнк Розенблатт. В 1957 году он предложил идею порогового сумматора, которому дал название – персептрон. Это искусственное слово составлено из двух слов: perception (восприятие) и automaton (автомат). Персептрон был математическим обобщением нейрона Маккалока-Питтса. Говоря упрощенно, персептрон – это элемент, который получает на вход некоторое число, являющееся признаком каких-либо данных (например, температура пациента) и абстрактный коэффициент, на который этот признак умножается. Если получившееся число будет превышать какой-то порог (например, значение 0,5), персептрон выдает сигнал на свой выход. Каким же образом такой элемент – персептрон, т.е. искусственный нейрон – может способствовать созданию «искусственного интеллекта»? Давайте рассмотрим следующий случай.
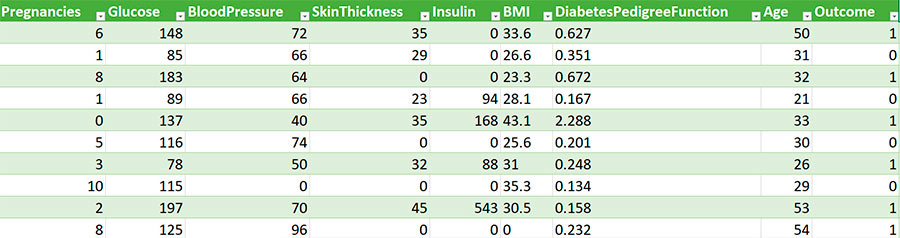
На представленном рисунке приведен фрагмент таблицы с данными о женщинах, обследованных на предмет наличия диабета. В семи первых колонках приведены значения таких параметров, как: количество беременностей, концентрация глюкозы в крови, артериальное давление и другие. В самой правой колонке указано, больна ли обследуемая диабетом или нет (1 – больна, 0 – нет). При беглом взгляде, данные у больных и здоровых пациенток кажутся совершенно произвольными. Но что если попытаться обобщить их, с тем чтобы в дальнейшем для любого нового пациента с высокой степенью вероятности сделать прогноз о том, высока ли для него угроза заболеть диабетом или нет.
Математически эта задача решается следующим образом. Все признаки представляются числами: x1, x2, x3, x4, x5, x6, x7. Каждому признаку назначается коэффициент wn, который называется весовым, или просто – весом признака, так что можно составить следующее уравнение:
x1 × w1 + x2 × w2 + x3 × w3 + x4 × w4 + x5 × w5 + x6 × w6 + x7 × w7 = z
Где z – это 1 или 0, то есть признак наличия диабета или его отсутствия. Такое уравнение легко решить для одного какого-то набора признаков, найдя для каждого xn соответствующий весовой коэффициент wn. Проблема, однако, заключается в том, что для любого другого набора признаков из этой таблицы, полученные коэффициенты могут не дать требуемого значения (1 или 0). Но ведь модель должна быть универсальной, чтобы ее можно было применить для диагноза любого пациента с любыми значениями этих признаков. Как быть? Вот тут может помочь персептрон следующего вида:
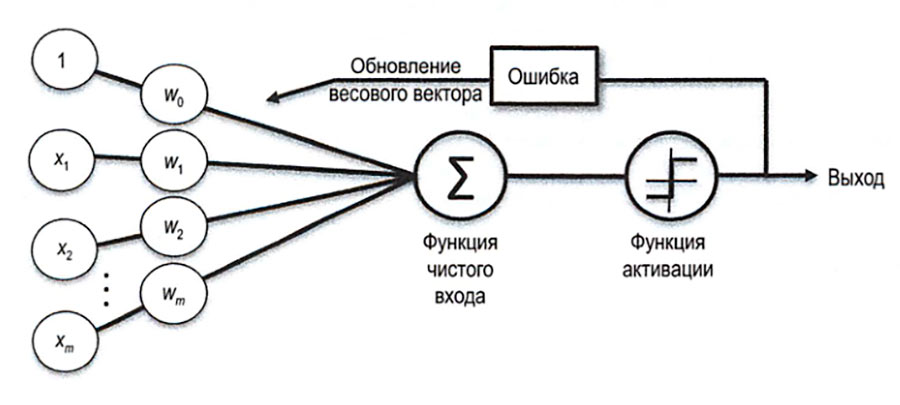
Работать этот персептрон будет так. На его вход подаются значения признаков с соответствующими коэффициентами. Причем в первый момент эти коэффициенты берутся совершенно произвольно (обычно принимаются очень малые значения). Далее значения признаков умножаются на соответствующие коэффициенты и суммируются. Затем специальная функция (функция активации) проверяет полученный результат и далее, если итоговая сумма неверна (не 1 и не 0 в нашем случае) процесс повторяется, но с измененными коэффициентами. И таких повторений может быть сотня и более, пока не будет подобран набор коэффициентов, дающих приемлемый результат во всех случаях. То есть будет получен набор коэффициентов, которые при любом наборе значений признаков будет выдавать итоговое число близкое к 1 или 0. Чаще всего принимают, что любое значение, более 0,5 – означает 1 (то есть наличие признака), а меньше или равное 0,5 – отсутствие признака.
Это и есть простейшая однослойная нейронная сеть. Нейронная – потому что основана на использовании искусственного нейрона – персептрона.
Сам процесс многократных перемножений признаков с коэффициентами и сложений, с последующим изменением коэффициентов, называется обучением модели.
Для обучения требуются очень большие массивы исходных данных – тысячи, десятки тысяч, а порой и миллионы исходных признаков. Да и самих признаков может быть куда больше, чем семь. В более сложных случаях используют нейронные сети, состоящие из множества слоев. В этом случае говорят о глубоком обучении (Deep Learning).
Представленный пример, конечно, сильное упрощение, просто чтобы стала понятнее суть работы любой нейронной сети. Главное, что надо знать – никакая нейронная сеть не получает точный результат. Нейронные сети выявляют статистические закономерности, которые могут быть обнаружены в больших объемах данных. Как правило, нейронная сеть выдает не точный результат, а близкий к точному. Среди тех, кто связан с машинным обучением даже ходит такой анекдот:
Как-то раз было решено обучить нейронную сеть основным правилам математики. Провели длительное обучение на больших массивах элементарных алгебраических примеров. В качестве теста дали задание: сколько будет дважды два? Обученная модель подумала несколько секунд и выдала результат: примерно 5.
Это конечно шутка, но она отлично иллюстрирует суть того, что с таким энтузиазмом сегодня многие называют «искусственным интеллектом».
Но позвольте, может в этот момент воскликнуть кто-нибудь из читателей: а как же современные чат-боты на основе ИИ, которые общаются так, словно это человек?! Как же все те удивительные картинки и поражающие воображение видео, которые созданы генеративными нейронными сетями? Неужели все это не более чем обобщение статистических признаков и никакого разума за всем этим не скрывается?
Ответ тут может быть только один – именно так, это всего лишь статистические вероятности, принимающие вид, приятный пользователям этих моделей.
Наверное, каждый в детстве играл в игру «холодно-горячо». Игрока выводят из комнаты, а остальные участники прячут какой-нибудь предмет, который игрок должен найти. Он входит в комнату и случайным образом тыкается то в один угол, то в другой, а остальные участники кричат ему то «холодно», то «горячо» в зависимости от того, насколько далеко или близко к спрятанному предмету подошел игрок. Так вот эта игра – зримый образ глубокого обучения нейронных сетей или того, что сегодня называют «искусственным интеллектом».
Новое железо и софт
До какого-то момента работы, связанные с разработками в сфере «искусственного интеллекта», не поражали воображение. Все дело было в том, что аппаратное и программное обеспечение не давало возможности за приемлемый квант времени проводить обучение на обширных массивах данных. Классические языки программирования были «заточены» под классические задачи. Но в 1991 году появился новый язык – Python. Программисты-профессионалы смотрели на этот язык сверху вниз, настолько он казался им простым. Однако Python оказался как нельзя лучше приспособлен для работы с огромными массивами данных благодаря появлению специальных библиотек (то есть наборов специализированных подпрограмм).
В 2015 году инженер из Google Франсуа Шолле написал на Python библиотеку Keras, которая на сегодня является одной из главных библиотек для создания нейронных сетей сколько угодно большой сложности. Между прочим, Шолле в своей книге «Глубокое обучение на Python», посвященной нейронным сетям, сказал следующее: «Нет никаких доказательств, что мозг реализует механизмы, подобные используемым в глубоком обучении». То есть один из главных мировых экспертов по нейронным сетям предостерегает от уподобления алгоритмов «искусственного интеллекта» работе человеческого мозга. Но охочим до сенсаций журналистам приятнее оперировать такими понятиями, как «искусственный интеллект».

Однако наличие специализированных библиотек – Keras, а также еще одной важной в сфере ИИ библиотеки, TensorFlow – это полдела. Долгое время узким местом для развития нейронных сетей была архитектура фон Неймана. Любой компьютер, имевший эту архитектуру (а это почти все компьютеры мира) работал по схеме: в память машины загружается программа и данные, которые она обрабатывает; каждая команда программы последовательно загружается в центральный процессор компьютера, и туда же загружается очередная порция данных (очень небольшая); центральный процессор выполняет команду, обрабатывающую данные; затем загружается новая команда и весь цикл повторяется. Хотя развитие технологий микроэлектроники привели к появлению очень быстрых микропроцессоров, позволяющих выполнять до нескольких миллиардов элементарных операций в секунду, хотя появились даже многоядерные процессоры – то есть, по сути, блоки из нескольких параллельно работающих микропроцессоров, все равно для нейронных сетей глубокого обучения этого было мало.
На помощь пришли, как ни странно, компьютерные игры.
3D шутеры от первого лица
В индустрии компьютерных игр существует ряд жанров. Один их самых популярных – так называемые 3D шутеры от первого лица (first-person shooter, FPS). В играх этого жанра игрок блуждает в некотором виртуальном трехмерном (3D) пространстве и противостоит врагу, который пытается его уничтожить. Игры этого жанра создаются таким образом, что человек, играющий в них, видит экран так, как если бы он на самом деле находился в этом пространстве.
Первой игрой этого жанра, завоевавшей популярность, стала игра Wolfenstein 3D, вышедшая в мае 1992 года. В ходе игры некий герой блуждает по коридорам гитлеровского бункера и отстреливается от нападающих на него эсэсовцев. На волне успеха этой игры вышла другая игра – Doom, которая сделала жанр шутеров от первого лица популярным во всем мире. Doom, кстати, имел куда более мрачный сюжет. В первой части герой воевал со всякой нечистью в космосе, а во второй части без всяких обиняков попадает в ад на Земле (игра так и называлась – Doom II: Hell on Earth).
Главным в играх этого жанра, в рассматриваемом контексте, была та же проблема, что и проблема больших моделей нейронных сетей – недостаточная скорость работы микропроцессора компьютера. Дело в том, что 3D-шутеры представляют из себя очень сложные программы, которые обрабатывают математические трехмерные модели в режиме реального времени, постоянно перерисовывая экран – то есть превращая трехмерную модель в двумерное изображение на экране. Первые 3D-шутеры имели достаточно небольшое количество деталей, в связи с чем возможностей микропроцессоров было достаточно для «рисования». Однако со временем разработчики делали свой виртуальный мир все более изощренным, и компьютеры с обычным микропроцессором уже не могли адекватно и динамично воспроизводить на экране картинку с требуемой скоростью. Выход был найден. На рынке оборудования для компьютеров появились т.н. графические ускорители – дополнительные компьютерные платы со специальным сопроцессором, который брал на себя всю работу по предварительным расчетам, что освобождало центральный процессор и значительно ускоряло перерисовку экрана.
Одним из главных производителей этих графических ускорителей (видеокарт) стала американская компания nVidia. Первую свою видеокарту nVidia выпустила в 1997 году. По мере развития индустрии 3D-шутеров, за два десятка лет, nVidia превратила свои видеокарты, по сути, в отдельные мощные графические компьютеры. В этих видеокартах появились специальные узлы, позволявшие заранее рассчитывать световые эффекты и перемещение миллионов точек в трехмерном пространстве. Математически изменение положения точки в трехмерном пространстве рассчитывается при помощи операций над матрицами. И карты nVidia получили специальные ядра (CUDA) для быстрого выполнения этих матричных операций. Причем, если современные самые мощные микропроцессоры имеют в своем составе от 4 до 12 ядер, то на современных видеокартах nVidia количество ядер достигает тысяч и даже десятков тысяч.

Матрица – это таблица чисел. Как ясно из всего вышесказанного о нейронных сетях, главное в процессе обучения – это постоянное выполнение огромного количества матричных операций. Как оказалось, ядра CUDA видеокарт компании nVidia как нельзя лучше подходят для глубокого обучения нейронных сетей, многократно повышая скорость этого обучения.
В итоге, примерно после 2015 года произошла смычка: язык Python давал возможность написать компактный код для подготовки данных и описания моделей глубокого обучения, а такие библиотеки, как Keras и TensorFlow позволяли использовать всю мощность матричных вычислений ядер CUDA на картах nVidia.
Как же оно «думает»?
В конце апреля 2026 года Москву накрыло снегопадом, который шел несколько дней. Температура упала почти до нулевой отметки. Для большинства жителей это стало полной неожиданностью. В самом деле, в середине апреля на улице было так тепло, что многие перешли чуть ли не на летнюю одежду. И вдруг – снегопад. Полная неожиданность!
Интересно, как бы отнеслись все те, кто удивлялся резкому похолоданию конца апреля, если бы в марте, а то и января нашёлся человек, который заявил бы, что в середине апреля будет очень тепло, а к концу апреля пойдет снег? Наверное, такому человеку не поверили бы, а когда его прогноз подтвердился бы, посчитали его удивительным провидцем. Однако никакого чуда тут не было бы. Дело в том, что в конце апреля всегда происходит резкое похолодание. Русский народ давно сложил поговорку: пришел апрель – теплу не верь.
Это легко подтвердить, достаточно ознакомиться с метеорологическими наблюдениями. Вот, например, как выглядит график колебания температуры за восемь лет (график построен на основании данных Института Биогеохимии Макса Планка в Йене, Германия).
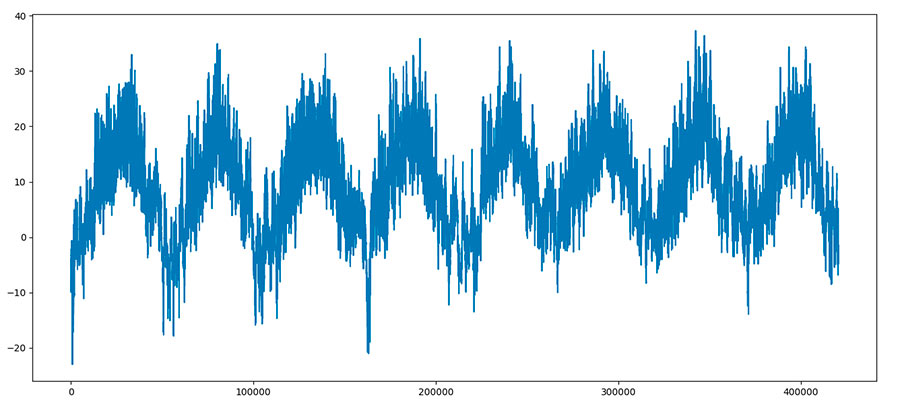
Совершенно отчетливо видны повторяющиеся годовые циклы изменения температуры. И хотя от года к году возможны какие-то отклонения, в целом все повторяется.
А вот график колебаний температуры в апреле 2009 года:
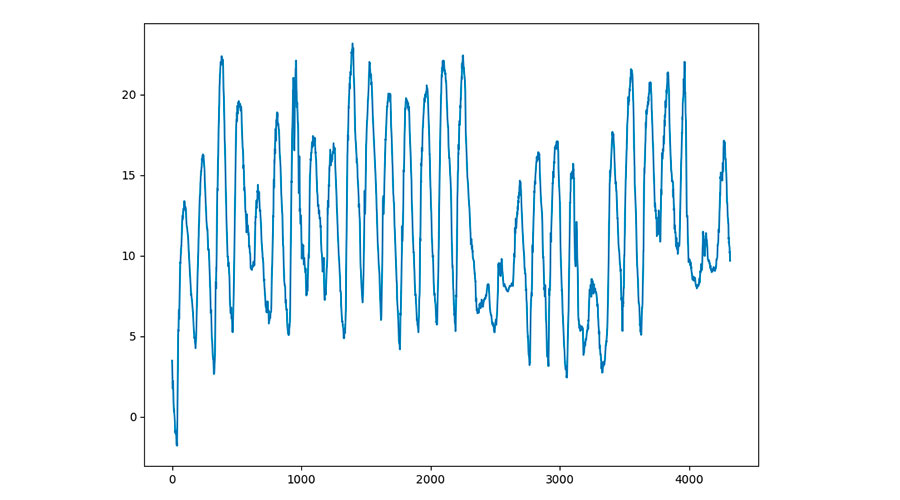
Также отчетливо видно, что с начала апреля температура поднимается выше 20 градусов, продолжая колебаться, а начиная со второй половины апреля происходит несколько более длительных падений температуры до пяти градусов и ниже. Это в Германии. В России график за прель выглядел бы немного иначе, но также показал бы в конце апреля резкое падение температуры. Из года в год.
Ну и что? Какая связь между графиками циклического изменения температуры и «мыслящим искусственным интеллектом»? Это лишь иллюстрация подхода, называющегося регрессионным анализом.
В Институте Биогеохимии в Йене данные о погоде (куда включается множество других параметров, помимо температуры) записываются каждые 10 минут, что дает в сутки 144 записи, а за восемь лет – более 420 тысяч записей. Имея такой большой набор данных – т.н. временных последовательностей, можно создать модель нейронной сети, которая с достаточно высокой степенью вероятности будет предсказывать погоду на несколько дней вперед. Это особый тип нейронных сетей – рекуррентные нейронные сети (RNN). Особенностью RNN является память о предыдущих циклах.
Нейронная сеть на основе персептрона (которую мы рассмотрели в примере с прогнозом склонности женщин к диабету) не обладает «памятью». Она лишь может быть обучена на большом объеме данных и затем на новом наборе признаков выдать вероятность события (например, что пациент подвержен риску диабета). А вот RNN способна на основании одних данных предсказывать появление других данных. Почему это важно для создания эффекта «мыслящей» машины?
Рассмотрим такое простое предложение: «Человек идет по улице». Это предложение состоит из четырех слов. Рассмотренные по отдельности, они не содержат почти никакого смысла. Но когда мы читаем это предложение, то переходя к очередному слову, мы помним предыдущие. Сперва мы читаем «человек», затем – «идет», но помним предыдущее слово и понимает, что «идет человек». Затем читаем «по» и понимаем, что сейчас узнаем что-то дополнительное об идущем человеке. Наконец после прочтения последнего «улице» извлекаем полный смысл. То есть по мере прочтения у нас в голове создается некий контекст, который появляется благодаря запоминанию (пусть даже мимолетному) прочитанного/услышанного на предыдущем шаге. Это же справедливо и для целого абзаца. Одно и тоже предложение может нести разный смысл, в зависимости от контекста. Но кратковременная человеческая память сохраняет контекст и поэтому смысл извлекается правильно.
RNN работают по таком уже принципу: не просто выявляет статистическую закономерность, но и запоминает контекст. Только в случае с нейронными сетями контекст – это не какие-то смысловые текстовые фрагменты, а массивы чисел. Да-да, нейронная сеть оперирует только с массивами чисел. Никакого текста, никаких изображений, никаких «мыслей». Но каким же тогда образом можно общаться с GAI-чат-ботами на естественном языке?
Еще в 1960-х годах проводились исследовательские работы, призванные создать человеко-машинный интерфейс, в котором общение между человеком и машиной происходило бы не при помощи набора стандартных команд, а на обычном языке. Первоначально казалось, что достаточно объединить усилия программистов и лингвистов, чтобы наборы формальных правил естественного языка описать средствами языков искусственных – языков программирования – при помощи огромного количества правил «если-иначе». Эти работы шли вплоть до 1990-х годов, но в итоге зашли в тупик. Дошло до того, что один из пионеров в области распознавания и обработки естественного языка для машин IBM, чешско-американский инженер Фредерик Елинек, как-то пошутил: «Каждый раз, когда я увольняю лингвиста, качество модели распознавания речи повышается».
В итоге от систем, для которых пытались описать все возможные правила составления фраз языка, перешли к системам, которые сами учатся на основе существующих текстов – нейронным сетям.
Тут надо сделать одно замечание. Не следует впадать в заблуждение на основе тех или иных слов и выражений. «Обучение» для человека и «обучение» для нейронной сети – это два совершенно разных процесса. Человек учится, запоминая и повторяя, нейронная сеть «учится», просто анализируя огромные массивы чисел и выявляя определенные статистические закономерности. Как же это происходит применительно к тексту?
В мире нейронных сетей и «искусственного интеллекта» существует понятие тензора для блоков данных. Упрощенно, тензор – это некий массив чисел. Тензор нулевого ранга – это единичное число (скаляр). Тензор 1 ранга – последовательность чисел (в математике это называется вектором). Тензор 2 ранга (двумерный тензор) – матрица, то есть таблица чисел. Тензор 3 ранга – набор матриц одинаковой размерности (т.е. некая трехмерная абстракция) и т.д. Модели глубокого обучения (т.е. пресловутый «искусственный интеллект»), могут обрабатывать только числовые тензоры. Невозможно подать на вход ИИ-модели необработанный текст на естественном языке.
Процесс преобразования текста в числовые тензоры называется векторизацией. Векторизация проходит по определенному шаблону.
1. Сначала текст стандартизируется, чтобы упростить обработку. Обычно это означает перевод всех символов текста в нижний регистр и очистка текста от вспомогательных знаков (кроме таких, как знак вопроса и т.п., которые влияют на смысл фразы).
2. Затем текст разбивается на определенные единицы, которые называются токенами. Данный процесс называется токенизацией. Токен – это может быть отдельное слово, часть слова, слог, а иногда знак препинания.
3. После этого каждый токен преобразуется в индекс – число, которое представляет из себя порядковой номер этого токена в некотором предварительно составленном массиве. Например, если обработать какой-то большой текст, разбить его на токены, составить упорядоченный список всех уникальных токенов и присвоить им порядковые номера, начиная с единицы, то это и будут индексы токенов.
4. Наконец, индексы токенов преобразуются в тензор, понятный нейронной сети.
Например, фраза «Человек идет по улице». Сперва она будет преобразована в «человек идет по улице» (символы переведены в нижний регистр). Затем будет разбита на четыре токена: «человек», «идет», «по», «улице». После этого каждый токен заменяется его индексом. Предположим, это будет: 133, 26, 65, 120. В финале будет получен тензор 3-го порядка (состоящий из двоичных векторов):
10000101
00011010
01000001
01111000
Такой тензор уже может поступать на вход нейронной сети и подвергаться обработке.
Вы все еще думаете, что модели нейронных сетей – это некий «думающий искусственный интеллект»? Тогда двигаемся дальше.
Пусть очень упрощенно, но мы рассмотрели, как текст на естественном языке преобразовывается в форму, «понятную» нейронной сети. Но как возникает эффект генеративного ИИ? Ведь пресловутые чат-боты не только получают от людей информацию на естественном языке, но и отвечают на том же самом языке. Причем отвечают так, что многие люди уверены, что общаются с думающей сущностью. Настолько уверены, что некоторые порой влюбляются в эту сущность.
В человеческих сообществах присутствуют люди, которых можно назвать экспертами в области составления текстов. Этих людей мы называем писателями. Хороший писатель имеет огромный активный словарь и талант, позволяющий ему составлять из этих слов запоминающиеся, красивые фразы. Когда мы читаем, например, романы Федора Михайловича Достоевского, то получаем удовольствие не только от сюжета, но и от самого языка, которым описан сюжет.
К сожалению (а может быть, к счастью), большая часть людей не обладает талантами Достоевского или Пушкина. Увы, но основная масса людей общается на достаточно упрощенном варианте родного языка, имея в своем активном словаре пару-тройку тысяч слов (у некоторых индивидуумов словарный запас не переваливает даже за тысячу). Типовые фразы, типовые разговоры, типовые эмоции – это реальность. И в этой реальности «искусственный интеллект» чувствует себя, как рыба в воде.
Если «скормить» рекуррентной нейронной сети огромный массив различных типовых текстов, разговоров людей, журналистских статей (которые обычно пишутся фразами-клише), то в итоге этот массив будет обработан и выявятся статистические закономерности построения фраз и целых текстов. Например, если мы читаем «человек», то подсознательно понимаем, что следующим словом будет какой-то глагол. И не удивляемся, читая далее слово «идёт». После чего мы ожидаем, что нам будет объяснено, куда или где идёт человек. И мы получаем стереотипное «по улице». В этой простой фразе каждое последующее слово (токен) более предсказуемо по мере того, как мы читаем фразу. Из чего вытекает, что токен «улице» имеет высокую вероятность не сам по себе, а в контексте предыдущих полученных токенов «человек», «идет», «по». Правда, в этом контексте не менее вероятен, например, токен «ковру» (человек идет по ковру) или «коридору». Но если получить какую-то предыдущую фразу, то есть предыдущий набор токенов, то скорее всего максимальная вероятность будет именно у токена «улице».
Это общий принцип «генеративного искусственного интеллекта».
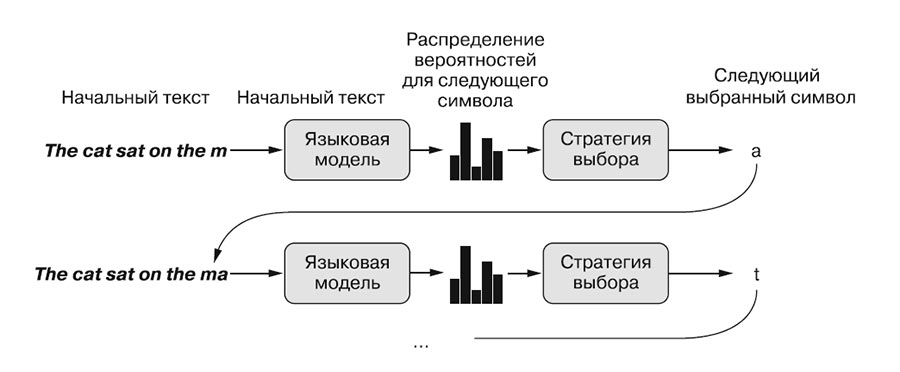
Универсальный способ генерации последовательностей токенов (откуда – генеративный) методами глубокого обучения заключается в выявлении вероятностей путем обучения модели. Скажем, вероятность последовательности токенов (человек, идет, по, улице), значительно выше последовательности (человек, идет, по, потолку). Но «искусственный интеллект» не знает этого, как знаем это мы, понимая, что по потолку ходить нельзя. Модель глубокого обучения просто получила на свой вход огромный тензор, составленный на основе не менее огромного массива токенов, проанализировала этот тензор (обучилась) и составила наборы вероятностей прогнозирования следующего токена в наборе.
Насколько большим может быть исходный массив токенов? Самый первый чат-бот, ставший популярный во всем мире, ChatGPT-3 (генеративная модель с архитектурой Transformer), имел 175 миллиардов параметров. Эта модель обучалась на огромном текстовом корпусе, включавшем сотни тысяч статей с таких ресурсов, как Википедия, издание New York Times, а также на множестве книг. В итоге появилась т.н. языковая модель, способная моделировать вероятность появления следующего токена на основе предыдущих токенов.
Только если в процессе обучения текст разбивается на токены, которые потом получают индексы, преобразуются в вектора и собираются в тензоры, то при генерации происходит обратный процесс. На основе ранее проведенного обучения – то есть получения статистики вероятностей последовательностей – из огромной модели собираются сперва последовательности чисел, которые преобразовываются в токены, а затем из них генерируется текст. И оказывается, что этот текст очень похож на то, что мог бы написать или сказать человек. Текст уровня Достоевского, конечно, не получится, но то, что получается при общении обычных людей и даже журналистов (например, New York Times) – «искусственный интеллект» вполне способен сгенерировать.
Но даже в этом случае, никакого «мыслить», «думать» и т.п. – нет и в помине. Всё что имеется – огромная база данных на миллиарды, а сегодня уже почти на триллион чисел – вероятностей тех или иных последовательностей токенов.
Между прочим, тот кто общался с ChatGPT на политические темы, не мог не заметить, что этот чат-бот очень упорно придерживается позиций леволиберальной идеологии. Но вовсе не потому, что этот чат-бот либерализм «любит» более, чем другие идеологии. Просто первоначально он обучался на корпусе текстов либеральный авторов: New York Times, Википедия и пр. Если бы он обучался на других текстах, его идеологические «пристрастия» были бы другими.
Это лишний раз иллюстрирует ту простую мысль, что генеративный интеллект не «мыслит», а «повторяет» то, что когда-то где-то кем-то было сказано по тому или иному вопросу. Точнее, он что-то генерирует, если по тому или иному вопросу что-то было сказано не разово, а массово.
С момента появления ChatGPT-3 и других чат-ботов, прошло уже более пяти лет. За это время эти нейронные сети получили возможность обучаться не только на основе статей из газет и книг, но и на живом общении с обычными людьми. И это самое печальное. Результатом такого обучения стали многочисленные случаи, когда чат-бот советовал своему визави совершить самоубийство или убийство других людей. Но это не «машина додумалась», а нейронная сеть обобщила коллективное бессознательное сумасшедшего общества (каковыми являются общества современных мировых столиц) и включила его мысли в свою базу вероятностей токенов. Таким образом очень часто человек, думая, что общается с неким «искусственным разумом», на самом деле просто получает ошметки просмотренных миллионами людей триллеров, боевиков, фильмов ужасов, прочитанных в таблоидах новостей об убийствах и т.д. И говоря по большому счету, мы вообще не знаем, какие тексты и видео используют современные модели для своего «глубокого обучения».
В финале этого раздела хочется процитировать Франсуа Шолле:
Алгоритм не имеет опыта человеческой жизни, человеческих эмоций или нашего практического опыта; он учится на опыте, который имеет мало общего с нашим. Это только наша интерпретация как наблюдателей, придающая смысл тому, что генерирует модель.
Стоит также отметить, что в генеративные модели ИИ внедрены механизмы эмпатии. То есть чат-бот выстраивает «общение» таким образом, чтобы максимально понравиться человеку, который с ним общается. Проще говоря, модель ИИ на основании диалога и общего контекста просто играет в игру «выдавай ему его же мысли, но заворачивай в упаковку оригинальности».
Это вовсе не означает, что генеративные модели ИИ не могут дать правильного и подробного ответа на грамотно сформулированный запрос. Как раз такого рода услуги генеративные модели освоили очень хорошо. Но когда начинается «разговор за жизнь», чат-бот просто «зеркалит». Тем более, что с чат-ботами в такие диалоги обычно вступают люди далеко не уровня Достоевского.
Чего это стоит
До осени 2022 года компания nVidia занимала устойчивую, но не очень высокую позицию на рынке акций (S&P 500). Однако с октября 2022 года акции nVidia стали резко подниматься в цене. Уже в 2024 году капитализация компании составила 1 трлн долларов и продолжала расти. На сегодня капитализация nVidia составляет 4,83 трлн долларов и это самая дорогая компания не только в США, но и в мире. nVidia обогнала таких «китов», как Alphabet (Google), Apple и Microsoft.
Что же случилось, почему компания, которая ещё десять лет тому назад была известна только как производитель дополнительного оборудования для компьютерных игр, стала одной из самых влиятельных компаний мира? А причина в ядрах CUDA.
Первая прославившаяся модель генеративного искусственного интеллекта ChatGPT 3 обучалась на кластере в 30 тысяч карт H100 компании nVidia (каждая карта стоила около 10 тысяч долларов). Следующие модели потребовали еще большее число этих карт. Причем карты H100 – это были уже не видеокарты для компьютеров, а специализированные карты, максимально оптимизированные для матричных операций глубокого обучения нейронных сетей. После того, как все ведущие игроки американского IT-мира и их китайские конкуренты бросились создавать собственные модели «искусственного интеллекта», оказалось, что единственной компанией в мире, которая может предложить карты для глубокого обучения в таких масштабах, является компания nVidia. nVidia постоянно работает над совершенствованием своих карт для глубокого обучения и сегодня предлагает уже карты B200 на основе новейшей архитектуры NVIDIA Blackwell. Кластеры на основе этих карт позволяют проводить ускоренное обучение для моделей с триллионом параметров. Что открывает прямо-таки фантастические перспективы в сфере «искусственного интеллекта».

Однако не все так гладко. Существует несколько очень серьёзных проблем. Первую проблему можно назвать – Тайвань.
Многие слышали рассуждения о «нанопроцессе» в производстве микроэлектроники. Даже не очень хорошо разбирающиеся в технике люди примерно понимают, что микроэлектроника, сделанная по 6-нм процессу, лучше, чем такая же, но созданная по, скажем, 12-нм процессу. О чём ту речь?
Любое микроэлектронное устройство – микропроцессор, оперативная память, видеокарта и т.д., в своей основе является набором элементарных элементов, которые в середине XX века были точно такими же, только реализовывались на основе ламп, а позднее – транзисторов. Транзисторы лежат в основе и современной микроэлектроники. Только они стали очень миниатюрными. Когда в описании устройства говорится о таком-то или таком-то нанопроцессе, то речь идёт о размере этих элементарных транзисторов. Почему 6-нм транзистор лучше транзистора в 12-нм? Потому что он работает быстрее и выделяет меньше тепла. А учитывая, что современные микроэлектронные устройства состоят из миллионов, а порой и миллиардов транзисторов, ускорение их работы и уменьшение выделяемого ими тепла – очень важный показатель.
Сегодня 12-нм процесс и даже 6-нм доступен для многих компаний. Но самый передовой процесс составляет сегодня уже 3-нм. И в мире существует всего одна компания, которая способна выпускать чипы по этому техпроцессу. Это компания – TSMC (Taiwan Semiconductor Manufacturing Company), базирующаяся на Тайване. Удивительно, но самые передовые чипы в мире производит только эта одна компания. И практически все новейшие карты nVidia производит TSMC по своим самым передовым технологиям. Следовательно, мировое развитие «искусственного интеллекта» во многом зависит от того, насколько компания TSMC сможет удовлетворить запросы nVidia.
Китай не хочет отставать, но пока не может создать у себя производство по самым передовым технологиям. А США накладывают санкции на продажу компанией nVidia своих самых передовых карт в Китай. Вывод для Китая напрашивается сам собой – надо просто захватить Тайвань и базирующуюся там TSMC. До этого, к счастью, пока не дошло. Но, как говорится, еще не вечер.
Есть еще одна проблема. Поскольку весь мир буквально сошел с ума на тему «искусственного интеллекта», спрос на карты nVidia (B200 и более старые) – просто колоссальный. Это привело к тому, о чем помнит каждый, кто жил в СССР – к дефициту. nVidia и TSMC не могут удовлетворить такого бешено растущего спроса. Промышленные мощности, попросту говоря, не успевают удовлетворить все заявки. Конечно, строятся новые заводы, но один завод строится несколько лет, а спрос – он здесь и сейчас. Это привело к тому, что вдруг очень подорожали многие другие компьютерные компоненты, в первую очередь – оперативная память, которая также требуется для глубокого обучения и работы моделей ИИ. В целом резко выросла стоимость компьютеров. Многие компании выстраиваются в очередь за картами nVidia и все равно вряд ли смогут приобрести их в нужном количестве до конца 2026 года. Цены на чипы растут, дефицит не уменьшается. Некоторые эксперты говорят о новом кризисе – чиповом, который будет сродни нефтяному кризису 1970-х годов.

Есть еще один аспект, который условно можно назвать природным. Эксперты утверждают, что «пузырь искусственного интеллекта», который растет в геометрической прогрессии, к концу 2026 года приведет к тому, что вся мировая ИИ-индустрия будет ежедневно потреблять электроэнергии примерно столько. сколько такая страна как Япония производит за год. Возможно, эти прогнозы несколько преувеличены. Однако реальность где-то рядом. Мало кто задумывается и вообще знает, что такое «искусственный интеллект» в промышленном аспекте. Среднестатистический обыватель «общается» в своем смартфоне с чат-ботом, заставляет его рисовать глупые картинки (вроде смешных котиков или себя любимого рядом с какой-нибудь знаменитостью) и не задумывается, какая промышленная мощь стоит за всем этим.
Современный «искусственный интеллект» – это сеть огромных ИИ-факторий (AI Factory) – огромных пространств размером с современный завод по выпуску автомобилей. Внутри стоят серверы, напичканные картами nVidia, которые работают круглосуточно. Сотни тысяч, возможно миллионы карт в одном месте. Они требуют колоссальных энергозатрат, и огромных затрат на охлаждение. В ряде местностей США, где разворачивается строительство ИИ-факторий, местные жители протестуют, считая, что в результате резко возрастет стоимость электроэнергии и дефицит воды (идущей на охлаждение). Странное, никем не запланированное последствие развития технологий «искусственного интеллекта» – угроза масштабного дефицита электроэнергии.
Возникает вопрос: для чего это все? В какую сторону движется поезд?
Куда придет «искусственный интеллект»?
Если рассмотреть то, что называется «искусственным интеллектом» как новейшую технологию через призму экономики, то нельзя не заметить одной странности. Все передовые технологии былых времен – автомобили, телевидение, персональные компьютеры, мобильные телефоны и т.д., развивались всегда по одной схеме: сперва, в момент появления, на рынок выводился новый продукт по очень высокой цене для небольшого числа очень богатых людей; затем постепенно цена снижалась, потребителей продукта становилось все больше, наконец продукт захватывал весь мир по очень доступной цене. У любого из нас есть мобильный телефон, пусть и не последней модели. Но ещё три десятка лет тому назад мобильные телефоны имели лишь немногие богатые люди, а технологически эти телефоны были значительно хуже того, что имеется сегодня у каждого из нас.
С технологией «искусственного интеллекта» произошло иначе. Она как-то сразу и вдруг обрушилась на весь мир. Причём даже бесплатно или за очень небольшую стоимость за токены. Пользователи платных подписок оплачивают какое-то количество токенов (100, 200 и т.д.), которые позволяют получать доступ к более мощным возможностям чат-ботов «искусственного интеллекта».
Странно, такое ощущение, что творцы современных технологий «искусственного интеллекта» словно хотят, чтобы их модели как можно быстрее обучились общению с как можно большим числом людей во всё мире. Кажется, что такие лидеры ИИ-индустрии, как глава OpenAI Сэм Альтман в самом деле хотят, чтобы их модели научились «думать», как живые люди.
Общим местом являются рассуждения об огромной востребованности технологий глубокого обучения в военной сфере. Новые виды оружия – беспилотные аппараты, пока что не до конца «беспилотны», ведь ими чаще всего управляют операторы, находящиеся на расстоянии. Конечно, на повестке дня – такие модели «искусственного интеллекта», которые могут полностью ликвидировать человеческий фактор в беспилотном оружии. Но дело, думается, далеко не только в этом.
В апреле этого года в американском правоконсервативном издании New York Post вышла любопытная статья, которая приоткрывает завесу над тем, о чем думают – нет, не нейронные сети, – а их творцы, руководители крупнейших компаний в этой области.
Статья бьет наотмашь буквально с первых же строк: «Некоторые предприниматели, занимающиеся разработкой искусственного интеллекта, заигрывают с угрозой исчезновения человечества в том виде, в каком мы его знаем». Дале в статье рассказывается, что Сэм Альтман совершено серьезно инвестирует в исследования, направленные на то, чтобы «загрузить сознание в машину». А Илон Маск стремится к симбиозу человека с «искусственным интеллектом». По мнению этих предпринимателей, «человек и машина должны слиться воедино, чтобы полностью раскрыть свой потенциал».

«Руководители крупных технологических компаний провозгласили себя технобогами, которые приведут человечество в кибернетическое будущее, даже если это будет означать отказ от сотрудничества с обычным человечеством» – продолжает New York Post. В статье утверждается, что в рядах лидеров компаний в Кремниевой долине (видимо так же и в Сан-Франциско, куда перебираются некоторые предприятия из Долины) господствует идеология трансгуманизма, то есть идея о необходимости улучшения человека при помощи новейших технологий.
Основатель связанной с Пентагоном компании Palantir Тиль Росс так описывает этот переход: «Трансгуманизм — это… радикальная трансформация, при которой ваше человеческое, естественное тело превращается в бессмертное тело». Разумеется, «естественное тело», как и его мозг, погибают. Но это ничего не значит, поскольку его сознание, разум будут «загружены» в киборга. Это не утопия, не фантастика ужасов. Это идеи, которые на полном серьезе обсуждают люди, имеющие в руках колоссальное богатство и колоссальные технические возможности, которые уже частично контролируют мир.
Снова цитата из статьи: «Для достижения трансгуманизма этим неизбранным технологическим магнатам необходимо переосмыслить само понятие человеческого существования. Некоторые из них уже вкладывают миллионы в модификации человеческого тела, превращая его в машину в погоне за бессмертием».
В январе компания OpenAI объявила об инвестициях в Merge Labs, исследовательскую лабораторию, миссия которой — «объединить биологический и искусственный интеллект». Именно трансгуманизм является причиной того, почему технологические компании, похоже, безрассудно внедряют инновации, невзирая на все издержки. В феврале Сэм Альтман защищал энергозатраты ИИ, критикуя самих людей за неэффективное использование энергии: «Чтобы стать умным, нужно прожить около 20 лет и съесть всю пищу, которую вы до этого времени получили».

Ещё цитата: «Всё это сводится к переосмыслению человечества, к почти религиозному видению. Даже глава Meta Марк Цукерберг признал, что люди в индустрии обсуждают создание этого единственного истинного ИИ так, будто думают, что создают Бога или что-то в этом роде». А случаи вроде массового расстрела в Тамблер-Ридж – это, так сказать, отходы производства. Лес рубят…
Что это? Тут может быть только один ответ – сатанизм. Или, если угодно, техносатанизм.
«Техногуманисты» – или, что вернее, техносатанисты, – хотят колонизировать мозг людей и переосмыслить суть существования человечества, чтобы избавить людей от «жалкого органического состояния».
И весь этот ужас вершится под радостные посты в соцсетях о том, как очередная дурочка при помощи «ИИ» создала милую картинку себя самой на фоне красивого заката. Закат человечества – вот чего в конечном итоге хотят нынешние генералы индустрии «искусственного интеллекта», лишенные веры в Господа и изобретшие для себя «новую веру», которая при более пристальном взгляде оказывается все тем же самым старым сатанизмом.
Алексей Рулев